







Дата-центры, обслуживающие ключевые для корпорации подразделения, расположены в разных регионах мира. В том числе и в Израиле, который островком стабильности по известным причинам не назовешь. Однако там создаются важнейшие для Intel продукты – микропроцессоры, и необходимостью обеспечить бесперебойную работу их проектировщиков совершенно невозможно пренебречь. На случай, если по непредсказуемым причинам дата-центры утрачивают способность нормально функционировать или нарушаются коммуникации с ними, принято строить центры аварийного восстановления (Disaster Recovery Site), способные принять на себя бОльшую часть обязанностей защищаемых сайтов. Понятно, что полное дублирование ресурсов основного дата-центра (а в нашем случае это тысячи серверов и сотни терабайт данных), требуемое для того чтобы за запланированный промежуток времени можно было перевести приложения с пострадавшего сайта на резервный, дело не дешевое. Особенно если учесть, что оборудованию DR-сайта предстоит не плодотворно трудиться, а пребывать в ожидании, не возникнет ли в нем необходимость.
Именно этой проблемой пришлось заняться IT-департаменту Intel в процессе строительства DR-сайта для израильского дата-центра. Вот какие цели были поставлены:
- инвестировать средства в правильное оборудование,
- добиться его максимально возможного использования вместо простоя,
- удержать стоимость на минимальном уровне.
Первым шагом для их достижения стал анализ того, как работают разработчики микропроцессоров, какими сервисами и приложениями они пользуются. Были выделены две модели работы. Первая, интерактивная, заключается в доступе с ноутбуков разработчиков к серверам дата-центра. Эти сессии отличаются высокой интенсивностью графических расчетов при очень малой латентности (менее 5 мс) коммуникационных каналов. Вторая модель, пакетная, состоит в запуске инженерами на пулах серверов дата-центра задач моделирования. В большинстве случаев такие задания могут быть выполнены с привлечением любых доступных серверах в глобальной сети Intel. При этом используется собственное ПО Intel для планирования задач. Чтобы соответствовать указанным моделям, создаваемый DR-центр должен:
- удовлетворять предъявляемым инженерами-разработчиками требованиям по латентности доступа, будучи в то же время значительно удален территориально от основной площадки, чтобы не подвергаться тем же рискам;
- содержать достаточное число серверов приложений, чтобы справиться с интерактивными сессиями;
- содержать достаточное число серверов для выполнения пакетных задач, которые не могут быть выполнены удаленно в других дата-центрах Intel.
Чтобы повысить использование ресурсов DR-центра, было решено перенести в него часть серверов основного дата-центра, загружаемых пакетными задачами. В обычных условиях эти серверы продолжают заниматься своим делом, а при аварии их можно переключить на обслуживание задач по восстановлению работоспособности, передав пакетные задачи на другие серверные площадки Intel. Перенос серверов обеспечил экономию на закупке оборудования для DR-центра около 2.5 млн. долл.
Следующим важным мероприятием стало создание механизмов репликации данных, позволяющих восстановить деятельность дата-центра в требуемые инженерами-разработчиками сроки. При этом была создана иерархическая система хранения данных на базе дисков с интерфейсами Fiber Channel и SATA. Первые, составляющие около 20% от общей емкости накопителей, используются для приложений с интенсивным вводом-выводом, что характерно для пакетных заданий. Более медленные SATA-винчестеры значительно дешевле и используются для хранения данных, которые могут быть востребованы только в аварийных ситуациях (для интерактивных задач). Применение SATA-дисков, как показали испытания, дает удовлетворительные результаты по производительности и позволило сэкономить более 250 тыс. долл.
Еще больший выигрыш получился при решении проблемы резервирования данных. Хотя backup-библиотека является неотъемлемой компонентой DR-центра, было решено отказаться от ее закупки. Тем более что входящие в нее накопители использовались бы только при аварийных ситуациях. Решение нашлось в видепереноса задач ежедневного резервного копирования с основного сайта на резервный. Вместо покупки нового оборудования было перевезено имеющееся, что дало экономию в 350 тыс. долл.
Кроме того, для размещения DR-сайта было решено не строить новое помещение, а расширить площади одного из уже имеющихся у Intel дата-центров. Разумеется, добавив также сетевую инфрастуктуру, мощности для электроснабжения и охлаждения. Кстати, для поддержания сетевой нагрузки DR-сайта, в основном возникающей при резервировании данных с рабочего дата-центра, потребовалось создать между ними WAN с пропускной способностью 155 Mbps.
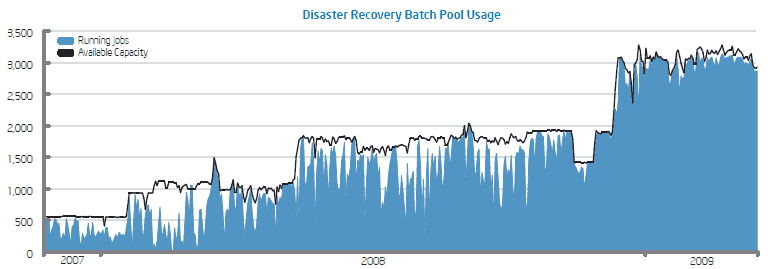
Число выполняемых пакетных заданий и имеющиеся для этого ресурсы. Intel удалось добиться почти 100-процентного использования серверов DR-центра (источник: Intel)
В итоге Intel удалось организовать DR-сайт с минимальным объемом инвестиций в новое оборудование, одновременно обеспечив высокую полезную загрузку находящихся в нем серверов (см. диаграмму). Правильность выбранной стратегии была подтверждена на проведенных год назад «учениях», в ходе которых на сутки были отключены сетевые коммуникации между основным и резервным дата-центрами и удалось в заданные сроки восстановить работоспособность 95% сервисов.
Источник: ru.intel.com






