







Понятие «кластер» может варьироваться в зависимости от возлагаемых на него ролей. Цель данной статьи — ознакомить читателя с полным спектром кластерных решений, представленных на рынке, и помочь определиться в выборе варианта для тех или иных задач. Рассмотрим каждый вид кластеров на конкретных примерах решений от Microsoft.
Кластеры балансировки нагрузки
Итак, первая задача: есть серверное приложение (например, веб-сайт). Необходимо, чтобы оно выполнялось параллельно на нескольких серверах средней или малой мощности, причем вычислительная часть должна легко расширяться в зависимости от нагрузки.
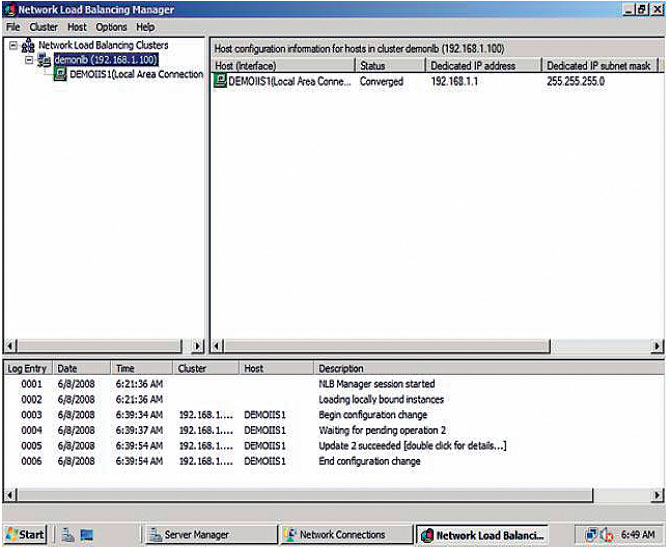
Использование NLB позволяет не столько повысить скорость выполнения отдельного серверного приложения (время одного запроса бесконечно мало в сравнении с количеством запросов), сколько перераспределять нагрузку между несколькими узлами с идентичными приложениями. Для этого в общей сети фермы, которая объединяет узлы между собой и обеспечивает доступ пользователей к узлам, NLB регистрирует общий — публичный — IP-адрес будущего кластера. Именно этот IP-адрес будет доступен пользователям для обращения к серверным приложениям. Кроме того, все узлы фермы добавляются в кластер с собственными — приватными — IP-адресами.
 |
Таким образом, благодаря NLB, создается эффективное серверное приложение, исполняемое на группе машин, фактически в линейной зависимости суммирующее общую производительность относительно количества узлов. При этом достигается высокая отказоустойчивость, поскольку под одной «точкой входа» к тому или иному сервису кластер может предоставить избыточное количество узлов одинаковой функциональности.
К недостаткам кластеров балансировки нагрузки следует отнести то, что серверное приложение должно быть приспособлено к работе в NLB, в частности, для сохранности данных и состояний пользователя на каждом узле.
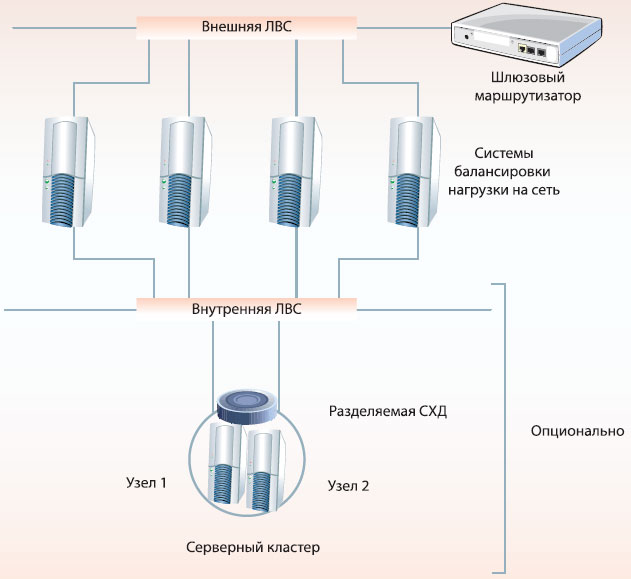 |
Пример построения фермы веб-серверов
Требуемые программные продукты: Microsoft Windows Server 2008 любых редакций. Начиная с самой младшей редакции, Web Edition, и заканчивая Datacenter Edition, Windows Server 2008 поддерживает службу Windows Network Load Balancing (WNLB) и может выступать в роли узла кластера NLB. Для предыдущих версий Windows Server (2003, 2003 R2) смотри соответствующие спецификации. Максимальное поддерживаемое число узлов в кластере — 32.
Требуемое аппаратное обеспечение: рекомендуемые Microsoft конфигурации к выбранной редакции ОС (беспокоиться о требованиях службы WNLB к памяти не следует — понадобится от 1 до 32 МБ в зависимости от нагрузки; в среднем — 2 МБ) и требования программного обеспечения, которое будет выполняться как задача; сетевой коммутатор с поддержкой протокола IGMP (желательно) или, если поддержка мультикастинга сетевым оборудованием не обеспечивается, — два сетевых адаптера на каждом узле.
Алгоритм процесса развертывания следующий:
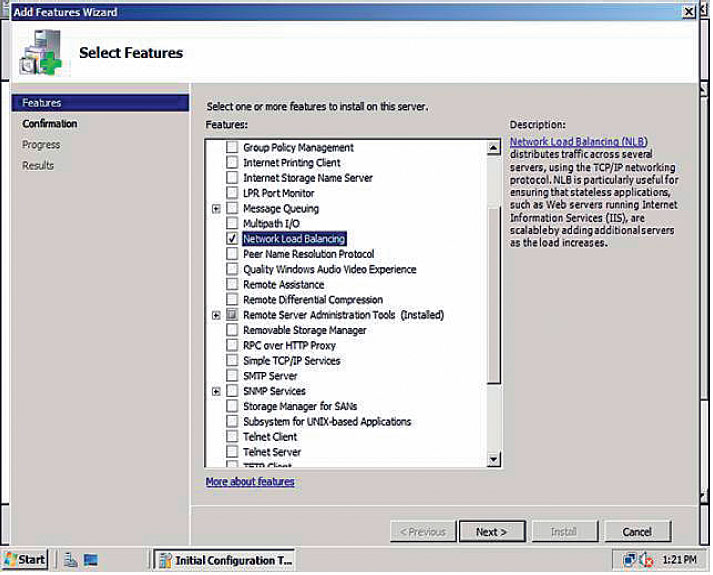
1. Установить на всех узлах будущего NLB-кластера службу Network Load Balancing, добавляется как Feature сервера Windows Server 2008.
2. Запустить оснастку управления Network Load Balancing Manager на любом из узлов и запустить мастер создания NLB-кластера командой New Cluster.
3. Мастер после указания имени первого узла позволяет определить сетевой интерфейс узла, где будет работать публичная сеть, приоритеты узла и, собственно, IP-адрес(а) и FQDN будущего кластера, режим работы кластера (юникаст, мультикаст, аппаратный IGMP) и, самое главное, правила распределения запросов между узлами кластера. Правило по умолчанию — это равномерное распределение всех запросов на все IP-адреса кластера независимо от порта, с «привязкой» конкретного отвечающего узла к IP-адресу клиента.
4. По завершении работы мастера, кластер конфигурируется и запускается в указанной конфигурации с одним узлом (определенным в мастере создания). Команда Add Host To Cluster запускает мастер добавления новых узлов в кластер. При этом не обязательно загружать консоль Network Load Balancing Manager на подключаемом узле. Мастер автоматически связывается с указанным сервером, проверяет наличие установленной службы NLB и только после этого конфигурирует службу и добавляет узел в указанный кластер.
К слову, даже без использования стороннего ПО служба NLB поддерживает различные «хитрые» конфигурации. Например, она способна одновременно поддерживать и кластер для определенных приложений, и работу серверов как отдельных узлов по любому адресу/порту с балансировкой только при сбое. Также в NLB один сервер может одновременно выступать узлом в различных кластерах.
 |
Кроме того, поскольку подход NLB по сути — сетевой, то критерий функционирования узлов для него ограничивается работой стека TCP/IP на узлах кластера. А работает ли на определенном порту узла какой-либо сервис (тот же IIS), NLB не проверяет и будет успешно передавать все http-запросы на узел, где служба IIS остановлена. Другими словами, работа службы NLB — отдать пакет узлу, а кто и как, и будет ли вообще его обрабатывать — ее уже не волнует.
Кластеры высокой доступности
 |
Кластеры высокой доступности обеспечивают гарантированную работу целевого приложения на одном из своих серверных узлов, объединенных высокоскоростной сетью для обмена состояниями процессов и общей дисковой СХД. В случае выхода из строя узла с приложением, вмешательства оператора, снижения производительности приложения до некоторого порога и т.п., целевое приложение запускается на другом доступном узле кластера. Поскольку данные приложения хранятся на общем дисковом массиве, они остаются доступными и при старте на другом узле, а сетевое имя и адрес маршрутизируется кластером между узлами. В отличие от NLB-кластера, который, по сути, является точкой обращения к приложениям, программы в HA-кластере представлены как отдельные сетевые серверные ресурсы. Каждый из таких сервисов имеет собственные IP-адрес и имя, отличные от IP-адресов/имен кластера и узлов. Кластеры высокой доступности обеспечивают надежное выполнение серверных приложений, но не повышают их производительность. Часто — даже наоборот, скорость работы несколько снижается, поскольку возникают накладные расходы на менеджмент ресурсов узла.
Таким образом, HA-кластер можно назвать «приложениецентричной» службой. Для нее важно, чтобы приложение получало все необходимые ресурсы — процессорное время, память, дисковую подсистему, сетевые соединения. Благодаря столь обширному контролю, пользователи всегда имеют доступ к приложению, которое мигрирует в случае сбоя отдельного узла на следующий свободный по задаваемому администраторами алгоритму. То есть, пожертвовав некоторым количеством серверов, которые в определенный момент простаивают «на подхвате» (пассивный режим, в отличие от активного режима того узла, где работает конкретная задача), можно быть уверенным, что аппаратный или программный сбой отдельного сервера не прервет бизнес-процессы организации.
В простейшем варианте HA-кластеры состоят из активного и пассивного узла. На активном выполняется задача, пассивный используется в случаях сбоев основного узла либо же при обновлении аппаратного или программного обеспечения. Для экономии аппаратных ресурсов порой используют конфигурации активный/активный, где на каждом из узлов выполняется своя задача. В таком случае при переносе задачи с одного узла на другой второй узел будет выполнять две задачи одновременно, но с более низкой производительностью обеих (если не сконфигурированы какие-то специальные приоритеты). Поэтому, если планируется отказоустойчивое решение для работы нескольких критических бизнес-приложений (или их отдельных служб), используется HA-кластер с 4, 8 или более узлами, один или два из которых работают в пассивном режиме, а остальные — в активном.
Однако наиболее важным нюансом при построении больших кластеров является общая дисковая система хранения данных. Она объединяет все узлы кластера и позволяет запущенным на них задачам получать доступ к необходимым данным независимо от узла, на котором они сейчас загружены. При большом количестве узлов и работающих на них «тяжелых» приложений, требуется очень высокая пропускная способность общей шины данных, а также большое количество выделяемых логических дисковых устройств на этой шине, поскольку каждому приложению необходимо, по крайней мере, одно такое устройство в единоличное пользование.
Пример построения HA-кластера
 |
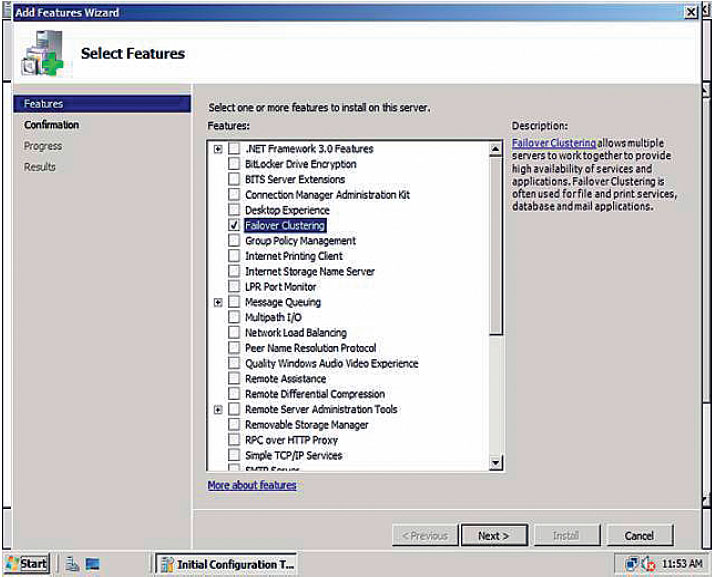
Требуемые программные продукты: Microsoft Windows Server 2008 в редакциях Enterprise или Datacenter — только они поддерживают работу кластера высокой доступности с применением Windows Server Failover Clustering. Количество узлов в кластере — 16, все узлы должны быть участниками одного домена Active Directory. Без Active Directory установить HA-кластер под управлением Windows Server Failover Clustering невозможно. Программное обеспечение, которое будет выполняться как задача, должно поддерживать работу в HA-кластере (или обеспечивать возможность переноса конфигурации, состояний между узлами).
Требуемое аппаратное обеспечение: рекомендуемые Microsoft конфигурации к выбранной редакции ОС, требования ПО (с учетом вероятности работы нескольких приложений на одном узле); два высокоскоростных (не менее 100 Мбит) сетевых интерфейса. Первый — для публикации в общей сети ресурсов кластера и приложений, другой — как внутренний интерфейс обмена данными между службами Windows Server Failover Clustering узлов для информирования о сбоях и режимах работы; общая дисковая подсистема, подключенная ко всем узлам, построенная на технологиях Fiber Channel, SCSI, iSCSI и в которой присутствует дисковое хранилище, оснащенное по крайней мере двумя свободными логическими дисковыми устройствами (одно — для общих данных служб кластеризации узлов Windows Server Failover Clustering, второе — непосредственно для данных кластеризуемого приложения). Если предполагается исполнение на узлах более одного приложения или приложение требует нескольких дисков, число логических устройств можно увеличить.
Алгоритм процесса развертывания:
1. Добавить серверы, которые будут работать как узлы HA-кластера, в домен Active Directory.
 |
3. Установить на всех узлах службу Windows Server Failover Clustering, которая добавляется как свойство сервера Windows Server 2008.
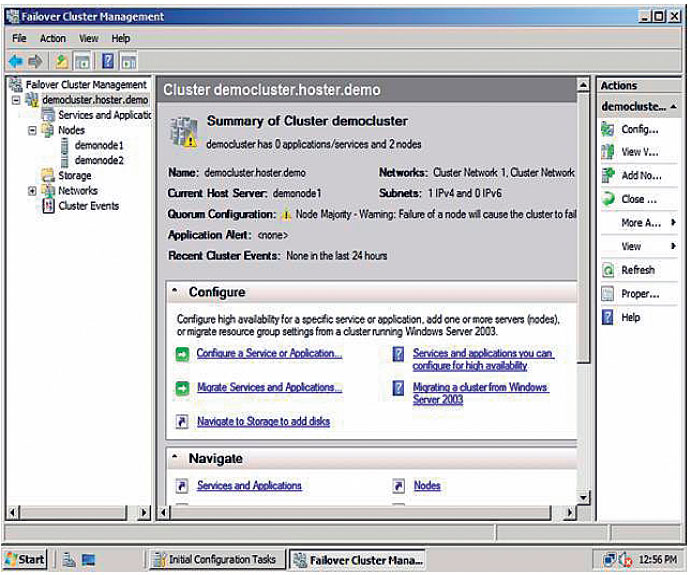
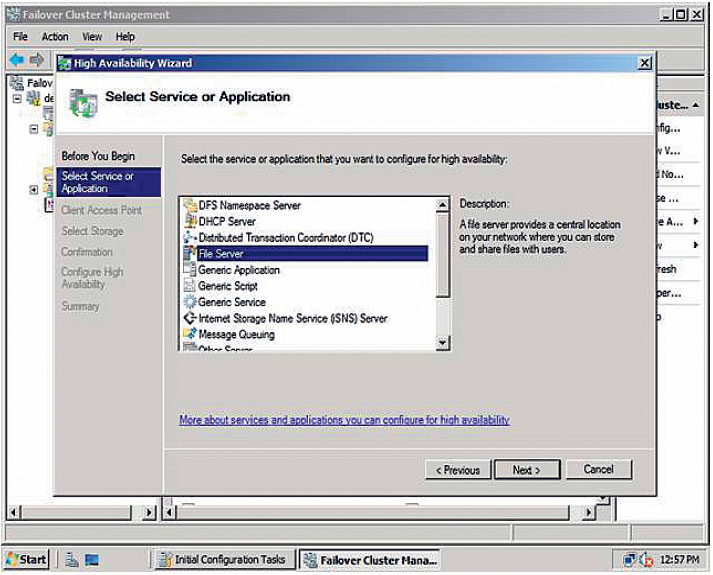
4. Запустить на одном из узлов оснастку Failover Cluster Management. Командой Validate a Configuration запустить мастер проверки конфигурации оборудования будущего кластера. Мастеру указываются имена всех узлов, которые будут задействованы в кластере, он автоматически находит всё требуемое оборудование и проверяет его в различных режимах работы. Процесс проверки занимает от 15 минут до нескольких часов. Рекомендуется внести все изменения, которые будут предложены мастером по окончании работы.
5. В оснастке Failover Cluster Management запустить командой Create a Cluster мастер создания кластера. После указания имен всех будущих узлов кластера и проверки наличия на них службы Windows Server Failover Clustering, мастер потребует только IP-адрес и имя будущего кластера. Процесс непосредственного создания кластера занимает буквально минуту.
6. После создания кластера в Failover Cluster Management будет отображена структура нового кластера. После проверки конфигурации, подготавливаем целевое приложение или сервис для работы в отказоустойчивом режиме. (Если требуется сервер БД, то на данном шаге его необходимо установить в кластерном режиме на каждый из узлов кластера, где он должен работать. Если работа сервера не будет нормироваться отдельными узлами, лучше устанавливать на все узлы. Процесс кластерной установки сервера БД только копирует исполнимые файлы приложения, а дальнейшая настройка и конфигурирование выполняется непосредственно в оснастке.)
 |
Если на HA-кластере работает несколько задач, нужно быть готовыми к тому, что они не всегда совместимы между собой на одном узле или не позволяют двухузловому кластеру работать в режиме активный/активный. Поэтому в решениях отказоустойчивой кластеризации на Windows Server 2008 рекомендуется использовать средства встроенной виртуализации Windows Hyper-V. Виртуальная машина с точки зрения кластеризации является обычным сервисом, выполнение которого следует остановить на одном узле, сохранив его данные в общем хранилище, и запустить на другом узле. При этом виртуальная машина не просто сохраняет данные (собственно, ее основные данные и так находятся в общем хранилище кластера) — сервис виртуализации приостанавливает работу переносимой виртуальной машины и сохраняет состояние оперативной памяти в виде файла на диске. Далее этот файл восстанавливается на другом узле как память запущенной там ранее остановленной виртуальной машины. Таким образом можно добиться более безопасного и изолированного исполнения нескольких несовместимых служб на одном узле, а также более полного использования аппаратных ресурсов, поскольку несколько виртуальных машин позволяют эффективнее распределять процессорное время между виртуальными процессорами.
О вычислительных кластерах на базе решений Microsoft см. приложение PCWeek Review №3 «Ресурсоёмкие вычисления».





