







Использование двух и более устройств, критичных для работоспособности системы, давным-давно применяется в технике и стало практически стандартом для обеспечения безотказности системы. Два двигателя у самолетов, независимые тормозные устройства в лифтах, питание от независимых энергоподстанций у АТС и других критических объектов инфраструктуры — все это стало привычным и кажется самим собой разумеющимся и вполне очевидным способом обеспечить бесперебойную работу, даже в случае выхода из строя одного из основных компонентов.
В серверных системах дублирование применяется практически повсеместно, как минимум на уровне обеспечения питанием — в наше время серверный корпус, не поддерживающий два независимых блока питания, еще нужно поискать.
Однако в тех случаях, когда нужно обеспечить действительно безотказную работу серверной системы, одним лишь резервированием питания обойтись уже не удается. Отказы могут произойти и у накопителей, и у дисковых контроллеров, и у материнской платы — потому в «настоящей» отказоустойчивой системе стараются дублировать все компоненты, начиная с подключения двухпортовых накопителей к двум разным контроллерам, и вплоть до резервирования полных серверных систем в рамках одного кластера, когда выход из строя целого сервера приводит лишь к перераспределению его нагрузки на остальные серверы, продолжающие работать.
Такой подход многократно повысил устойчивость кластера к единичным неисправностям, но все равно оставалась одна критичная подсистема, простое дублирование «в лоб» которой было либо невозможно, либо резко снижало производительность кластера в целом: сетевая инфраструктура. Действительно, при всей устойчивости к отказам питания, отдельных накопителей, серверов в целом — отказ коммутатора, объединяющего их в единый кластер, приводит к полному отказу всей конструкции. А установка двух коммутаторов, работающих независимо, — создает массу трудностей в маршрутизации потоков данных, решение которых довольно нетривиально, ресурсоемко и не гарантирует доставку каждого пакета адресату.
Решить эту проблему помогли растущие требования к пропускной способности сетей — для ее «бесплатного» (ну, почти) увеличения научились агрегировать Ethernet-линки, объединяя несколько физических соединений в одно логическое (link aggregation group, LAG). Это потребовало некоторых дополнительных усилий как со стороны хостов, так и со стороны коммутаторов, но принесло несомненную пользу, практически линейно расширив полосу пропускания такого объединенного линка при использовании недостаточно скоростных физических соединений. «Бонусом» к скорости приложилось и повышение отказоустойчивости кластера: теперь выход из строя физического соединения (отказ PhY, случайное выдергивание кабеля и т.д.) приводит только лишь к снижению полосы пропускания линка, а не к потере целого хоста из кластера.
Но сам коммутатор все равно оставался в единственном числе и представлял собой узловую точку, отказ которой сразу же делал неработоспособным весь кластер.
Выход был найден с использованием функции многоузловой агрегации соединений (multi-chassis link aggregation group, MLAG), когда два или более физических коммутатора объединяются в единое логическое устройство при помощи специального отдельного соединения друг с другом (inter-peer link, IPL). Через это соединение синхронизируется работа коммутаторов, и в случае сбоя одного из них сигнал поступает к остальным коммутаторам в группе для перераспределения нагрузки.
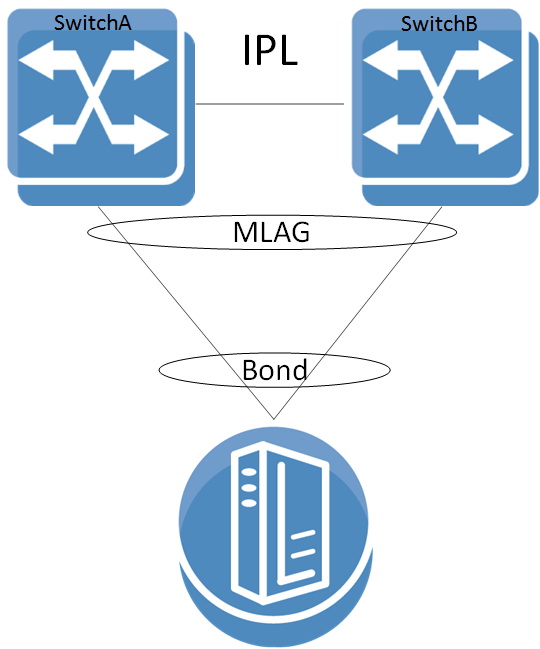
Такая схема подключения получается совершенно прозрачной со стороны хоста. Он «видит» точно такой же агрегированный логический линк, какой использовался бы в привычном варианте с одним коммутатором, и в то же время распараллеливает узловую точку отказа (коммутатор) на несколько физических устройств. Выход из строя любого из этих устройств не приводит к отказу кластера в целом — его работоспособность, пусть и с пониженной производительностью, сохраняется, пока работает хотя бы один физический коммутатор. Благодаря подобной прозрачности технология MLAG не требует никакой дополнительной поддержки со стороны хоста и работает с любыми устройствами, поддерживающими агрегацию Ethernet-соединений.
Именно такие устройства предлагает компания Mellanox Technologies — американский производитель телекоммуникационного оборудования с штаб-квартирой в г. Саннивейл, Калифорния. Практическая реализация технологии MLAG обеспечивается ее поддержкой со стороны операционной системы, управляющей работой коммутатора — Mellanox Onyx. На базе этой ОС работает вся линейка высокопроизводительных коммутаторов Mellanox Spectrum и Mellanox Spectrum 2. Оснащенные от 16 до 128 портов с поддержкой скоростей соединения от 1 до 400 гигабит в секунду, эти коммутаторы предназначены для построения центров обработки данных любого масштаба с любой степенью резервирования оборудования, обеспечивая любой заданный уровень отказоустойчивости при сохранении гарантированной доставки пакетов с высочайшей производительностью и предсказуемой стабильной латентностью.
Для достижения максимальной производительности сетевого соединения в хост-системах применяются новейшие сетевые интерфейсы Mellanox ConnectX-6 Dx, обеспечивающие линк со скоростью до 200 Гб/с при конфигурировании в однопортовом варианте. В двухпортовом варианте карта поддерживает два порта, работающих со скоростью от 10 до 100 Гб/с.
Сетевые интерфейсы Mellanox ConnectX-6 Dx выпускаются в разных форм-факторах (низкопрофильные карты PCIe x16, малогабаритные форм-факторы OCP 2.0 и 3.0), поддерживают 256-битное AES аппаратное шифрование, виртуализацию и совместимы с платформами x86/x64, PowerPC и ARM.






