






Для многих украинских коммерческих и государственных организаций актуален вопрос перехода от бумажного документооборота к электронному. Растущие компании рано или поздно приходят к необходимости внедрения систем, способных формализовать процессы обмена информацией между подразделениями и предоставить руководству эффективные средства контроля исполнения распоряжений. На базовом уровне функции обмена документами и совместного редактирования файлов может выполнять даже почтовый сервер, однако для построения корпоративных систем требуются специализированные решения.
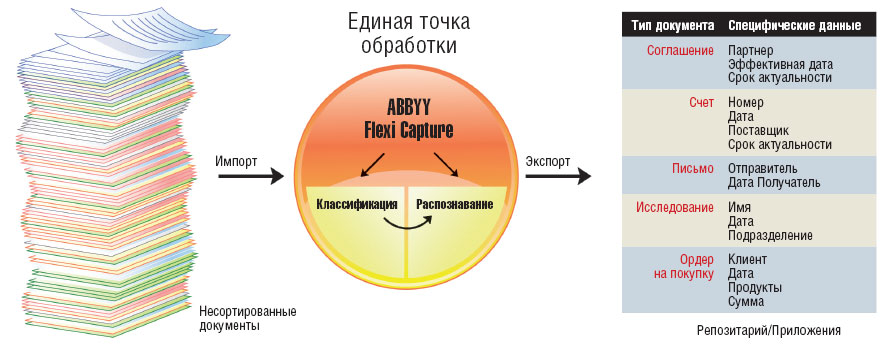 Подход к автоматизации распознавания ABBYY |
Технологии электронного документооборота и управления контентом (Enterprise Content Management, ECM) тесно взаимосвязаны. Как правило, к задачам ECM относят регистрацию входящих документов, управление маршрутами, совместную работу с документами, обмен информацией и взаимодействие в рамках проектов, доступ к документам на порталах и сайтах и др. Некоторые из этих функций присущи и системам электронного документооборота. Это приводит к возникновению путаницы в терминологии и вызывает сложности у компаний, перед которыми стоит задача автоматизации.
Типы документов
Бумажные документы можно разделить на две категории: структурированные и неструктурированные. К первой категории относятся разнообразные анкеты, бланки, отчеты, листы опросов и другие подобные документы, которые могут быть заполнены как от руки, так и компьютерным способом. Ко второй категории принадлежат печатные листы, статьи в газетах, информация, размещенная в интернете и т.п.
Автоматизация ввода информации из структурированных документов на сегодняшний день хорошо освоена. Однако в последнее время компании проявляют все больший интерес к автоматизации ввода неструктурированной информации. Бизнес некоторых организаций напрямую зависит от качества анализа информации в открытых источниках. Это относится, например, к компаниям, работающим на бирже — правильное прогнозирование котировок позволяет увеличить прибыль. В таких компаниях анализом данных, необходимых для прогнозирования, занимаются целые отделы. Современные системы обработки неструктурированных документов предлагают развитые средства автоматизации этих процессов, что предоставляет заказчикам возможность значительно повысить эффективность работы.
Этапы ввода информации
Перевод документов из бумажного в электронный вид состоит из нескольких этапов. На первом осуществляется сканирование или фотографирование документов (с развитием цифровой фототехники второй способ приобретает все большую популярность). Следующий этап – классификация, в ходе которого происходит разделение документов разных типов (например, входящие письма отделяются от газетных статей). Эту работу можно выполнять полностью в автоматическом, полуавтоматическом или ручном режиме. В ручном режиме оператор визуально определяет тип документа и заносит информацию в систему. Полуавтоматический режим предполагает разделение разных типов документов промежуточными маркирующими листами: например, сначала поступает письмо, затем следует разделительный лист, затем — газетные статьи. Поэтому для полуавтоматического режима требуется предварительная сортировка документов. Наконец, наиболее совершенный, автоматический способ ввода информации предусматривает, что система самостоятельно определяет тип документа на основе расположения, характера, содержания текста и других признаков.
После сканирования (фотографирования) и классификации необходимо извлечь информацию и присвоить электронному документу атрибуты. Практически любой документ содержит поля данных: дату, имя автора, название и т.п. Как и классификация, присвоение атрибутов может быть выполнено ручным, полуавтоматическим или автоматическим способом, причем в автоматическом режиме для повышения точности обычно задействуют разнообразные справочники, сверяясь с которыми система может снизить количество ошибок.
Перечисленные процедуры необходимы для последующего занесения информации в электронную базу данных, индексации и организации поиска. Обычно автоматические и полуавтоматические этапы выполняются в фоновом режиме.
Часто по прошествии некоторого времени занесенные в электронную базу данных документы требуют ретроатрибутирования. Эта необходимость возникает в том случае, если на этапе разработки не удалось предусмотреть все атрибуты, которые требуются в дальнейшем, например, указать дополнительно язык документа.
Решения ABBYY
Исторически компания ABBYY развивала три направления: ввод документов, форм и прикладную лингвистику. Сегодня в каждой из этих категорий компания предлагает продукты разного класса, адресованные конечным пользователям, системным интеграторам и разработчикам. Помимо этого ABBYY интегрировала продукты всех перечисленных категорий в единое решение — FlexiCapture, которое позволяет обрабатывать формы и неструктурированные документы в одном пространстве.
Программное обеспечение ABBYY FlexiCapture реализует ряд технологий для проверки соответствия представленной в анкете информации. Это обстоятельство имеет принципиальное значение при обработке структурированных документов, поскольку результатом этой процедуры является занесение информации в базу данных. Для корректного выполнения этой операции необходимо провести предварительную проверку каждого поля в анкете на соответствие типа данных ожидаемому результату (например, не указан ли в цифровой графе текст), длины слов и других параметров.
Автоматизированные системы ввода бумажных документов востребованы как государственными учреждениями, так и коммерческими компаниями. Для автоматизации обработки документов в банках ABBYY предлагает специализированный программный продукт “FineReader Банк”, который содержит средства анализа типичных для банковского бизнеса слабоструктурированных документов – платежных поручений.
С помощью ABBYY FlexiCapture можно автоматизировать прием документов от клиентов, заказывающих платежные карточки. Этот процесс предусматривает перевод в электронный вид заявления, анкеты, копии паспорта, справки из налоговой инспекции и др. При этом необходимо убедиться, что клиент предоставил полный перечень необходимых документов, проверить, действительно ли поданные документы принадлежат одному и тому же лицу, сверить фотографии, фамилии в заявлении и в справке о присвоении идентификационного кода и т.п. Решения на основе ABBYY FineReader Банк позволяют полностью или частично автоматизировать подобные процессы.
Современная технология оптического распознавания позволяет обрабатывать в том числе и рукописный текст при условии раздельного написания букв. Эти возможности широко востребованы коммунальными предприятиями, которые сталкиваются с задачей обработки множества заполненных от руки квитанций, бланков и других подобных документов.
Крупным компаниям ABBYY предлагает решения, позволяющие совместить процессы ввода информации с бумажных и электронных форм. Подобная система внедрена, например, в Литве, где каждый клиент компании может выбрать удобную форму предоставления информации.
Организациям, которые постоянно сталкиваются с распознаванием неструктурированных текстов, ABBYY предлагает перенести эту задачу с рабочего места сотрудников на сервер. Такая функциональность реализована в ABBYY Recognition Server. При использовании этого продукта процесс сканирования и распознавания бумажных документов становится управляемым сервисом, доступ к которому можно регламентировать централизованно. Такой подход характеризуется сразу несколькими преимуществами:
1) отпадает необходимость в оборудовании рабочих мест сканерами и программным обеспечением;
2) появляется возможность планировать процесс распознавания во времени: работник может загрузить бумажные документы или фотографии страниц вечером, а утром получить распознанные электронные файлы;
3) удается оптимизировать процесс ввода документов и минимизировать время, которое работники тратят на техническую процедуру распознавания.
Помимо этого переход к сервисно-оринетированной архитектуре предоставляет дополнительные возможности для интеграции со сторонним программным обеспечением, внедрения гибких механизмов экспорта и импорта данных.
Для мобильных устройств ABBYY предлагает средства разработки Mobile SDK, используя которые производители программного обеспечения могут встраивать технологии распознавания в свои продукты. На основе ABBYY Mobile SDK можно создавать ПО для распознавания визитных карточек, паспортов и других подобных документов на мобильных телефонах и КПК. Такие продукты востребованы как конечными клиентами, так и корпоративными заказчиками, которые используют мобильные устройства в бизнесе.
ABBYY сотрудничает и с разработчиками сканеров и многофункциональных устройств (МФУ), лицензируя технологии ввода документов и оптического распознавания для встраивания в низкоуровневое программное обеспечение. В частности, некоторые МФУ позволяют автоматически перевести в электронное представление бумажный документ, при необходимости провести коррекцию текста, а затем растиражировать обновленный документ. Эти операции можно произвести непосредственно на МФУ без задействования ПК.
Заключение
Внедрение технологий оптического распознавания документов открывает перед организациями возможность автоматизации рутинных процессов ввода и обработки структурированной и неструктурированной информации. Повышение точности распознавания текста, разработка технологий обработки заполненных вручную форм значительно повышает эффективность взаимодействия государственных и коммерческих учреждений с клиентами. Автоматизация этих процессов предоставляет руководству мощные средства для анализа больших объемов информации и способствует принятию более точных и своевременных решений, что оказывает прямое влияние на эффективность бизнеса.
| КОММЕНТАРИЙ ЗАКАЗЧИКА Николай Колесник, заместитель проректора по учебной работе Сумского национального аграрного университета
С помощью продукта ABBYY FormReader мы проводили репетицию внешнего независимого тестирования знаний выпускников 11 классов школ г.Сумы. В тестировании приняло участие 1690 человек, т.е. около 95% учащихся выпускных классов. Тестирование проходило по 3 предметам: украинский язык (1690 человек), история (923 человека), математика (777 человек). Проверка работ с обработкой результатов заняла 8 часов (3 часа — сканирование, 5 часов — обработка и верификация). Средства ABBYY использовались также в мультимедийном режиме при проведении городской компьютерной олимпиады по истории — с их помощью 300 форм были обработаны всего за 20 минут. В обоих случаях программные продукты ABBYY продемонстрировали высокий уровень распознавания. Мы на собственном опыте убедились в том, что ABBYY FormReader является мощным инструментом для внедрения независимых форм контроля знаний в учебных заведениях. |

