







Сегодня в Украине многие компании приступают к реализации центров обработки данных, активно развивается отрасль высокопродуктивных вычислений. Для построения вычислительных и коммерческих кластеров, требовательных к высокой пропускной способности сети, применяются специализированные интерфейсы.
 |
infiniband
InfiniBand является самой быстро развивающейся технологией межузловых высокоскоростных коммуникаций. Коммуникационная среда InfiniBand отличается от прочих тем, что эту технологию поддерживает и совершенствует достаточно большое количество производителей аппаратного обеспечения. Практически все разновидности высокоскоростных интерконнектов, за исключением Gigabit Ethernet, являются разработками какой-либо одной компании, которая занимается развитием интерфейса, производством аппаратных решений и разработкой необходимого программного обеспечения. Благодаря наличию конкуренции не только внешней — с другими видами интерконнектов, но и внутренней, среди производителей аппаратного обеспечения и разработчиков ПО для InfiniBand, именно эта коммуникационная среда является наиболее динамично развивающейся.
Типичными параметрами для коммуникационной среды этого класса являются реальная скорость передачи данных от 800 до 1400 МБ/с и время задержки на уровне 3-6 мкс в зависимости от используемых платформ и типов интерфейсов. Латентность несколько выше, чем у SCI или Quadrics QsNet (о них речь пойдет ниже), что, однако, компенсируется большой пропускной способностью InfiniBand. Для этого интерконнекта характерна коммутируемая топология, которая позволяет строить достаточно крупные и мощные кластеры. Стоимость решений на основе infiniband сравнительно невысока, что обусловлено уже упоминавшейся конкуренцией между производителями аппаратных интерфейсных контроллеров. Для больших кластеров, содержащих значительное количество узлов и обладающих соответствующей производительностью, выбор коммуникационной среды InfiniBand является наиболее выгодным в плане соотношения цена/производительность.
Сейчас в продаже имеется множество адаптеров InfiniBand, ориентированных на различные сегменты рынка. В частности, были выпущены адаптеры, которые используют оперативную память сервера и не имеют выделенной памяти.
В перспективе ожидается появление материнских плат, оснащенных встроенными портами InfiniBand и Gigabit Ethernet. Собственно, некоторые разработчики предлагают такие платы уже сегодня.
Лидером среди производителей infiniband для бизнес-приложений и крупных кластеров является компания Voltaire, которая на его основе построила множество решений для датацентров. Кроме того, Voltaire выпускает специализированные коммутаторы для объединения infiniband-сетей и сетей Gigabit Ethernet, Fibre Channel. Стоимость её продуктов и решений несколько выше, чем у Mellanox, но с их помощью можно реализовывать более мощные решения. Кроме того, компания обеспечивает заказчикам высокий уровень поддержки.
Еще один лидер в области infiniband-решений — компания Mellanox. Её продукты сегодня являются одними их самых недорогих на рынке высокоскоростных коммуникаций. Осенью 2004 года Mellanox анонсировала возможность достижения скорости передачи данных 20 Гбит/с, а на последней суперкомпьютерной конференции — до 60 Гбит/с при использовании интерфейса InfiniBand 12x. При этом адаптеры InfiniBand демонстрируют задержку на библиотеках MPI порядка 3-4 мкс, работая на шине PCI- Express, и порядка 5–7 мкс на шине PCI-X.
Поддержка InfiniBand была наиболее полно реализована во втором релизе Oracle 10g, так называемой GRID-базе данных Oracle. Высокопроизводительные расчеты все чаще проводятся на базе кластеров, соединенных InfiniBand. Уже несколько лет назад доступны математические библиотеки MPI, разработанные в университете Огайо и в MCSE, а сегодня появляется множество коммерческих версий, включая разработки Intel и HP.
В последних версиях продуктов InfiniBand достигнута латентность при использовании некоторых платформ на уровне 2.8 мкс, что в полтора раза меньше, чем у адаптеров предыдущего поколения. Наиболее распространены аппаратные решения InfiniBand от компаний Voltaire, Mellanox, Topspin (сейчас Cisco), Pathscale и SilverStorm Technologies (две последние сейчас являются собственностью Qlogic).
Для больших конфигураций применяется топология Fat Tree. К используемому программному обеспечению относятся драйверы от производителей аппаратных средств, версия MPICH университета Огайо, а также коммерческие продукты от Scali и MPI Software Technology.
Компания PathScale представила рекордные результаты производительности своего нового интерконнекта PathScale InfiniPath. Адаптер PathScale InfiniPath обеспечивает рекордно низкое время задержки интерконнекта (до 1.3 мкс на библиотеке MPI) при пропускной способности 10 Гбит/с. PathScale InfiniPath подключается напрямую к системной шине HyperTransport. В качестве интерфейса он использует стандартную архитектуру InfiniBand.
Преимуществом PathScale InfiniPath является рост производительности с увеличением количества процессоров в вычислительном узле, что особенно актуально в связи с тенденцией перехода к использованию многоядерных процессоров. Так, при применении на узле четырех процессоров PathScale InfiniPath позволяет достичь рекордной цифры в 8 млн. сообщений в секунду. Наибольшая производительность достигается при передаче сообщений маленького размера.
NUMAlink
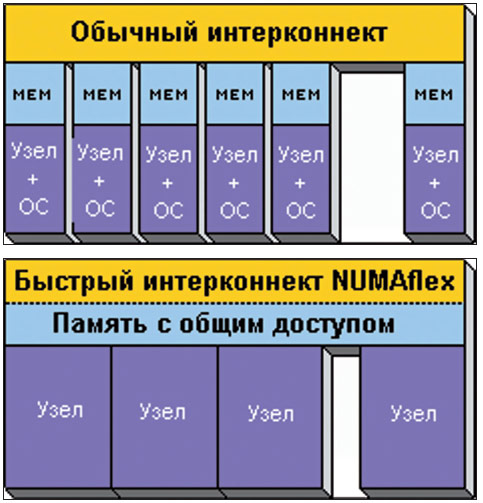
Быстрый доступ к памяти важен для достижения сбалансированной, устойчивой производительности микропроцессоров, способных совершать более миллиарда операций в секунду при обработке технических задач и обслуживании крупных баз данных. Данные, которые передаются через коммутатор SGI NUMAlink, совершают полный оборот всего за 50 наносекунд. Латентность при передаче пакетов MPI (Message Passing Interface — интерфейс передачи сообщений, который используется для обмена данными между частями задачи, работающей, например, в разных узлах вычислительного кластера) у NUMAlink 4 равна 1 мкс, а полоса пропускания на канал — 3200 Мб/сек в каждую сторону (дуплекс).
Для сравнения многие стандартные кластерные интерконнекты демонстрируют полный оборот за 10 000 наносекунд и более. Кроме того, технология SGI NUMAlink является единственным интерконнектом, обеспечивающим режим глобальной памяти с общим доступом между узлами.
Архитектура NUMAFlex построена с использованием интерконнекта NUMAlink. Это технология глобальной памяти с общим доступом, основной особенностью которой является адресация любым процессором всего объема памяти до 24 TB под одним ядром Linux. Применение этой архитектуры позволяет добиться наивысшей производительности при передаче данных.
Системы с глобально адресуемой памятью обеспечивают прямой, эффективный доступ ко всем данным, исключив необходимость их перемещения через средства ввода/вывода или через сетевые каналы, которые зачастую существенно перегружены. При этом достигается очень высокая производительность, поскольку латентность при связи с доменом памяти в 1000 –10000 раз меньше, чем при работе через системные средства ввода/вывода или сетевые каналы. В кластерах, архитектура которых не предусматривает глобальной памяти с общим доступом, преодоление этого ограничения обычно происходит перемещением копий данных в форме сообщений, что крайне усложняет программирование и снижает производительность, увеличивая время, которое процессоры вынуждены проводить в ожидании данных.
Gigabit Ethernet
Сегодня Gigabit Ethernet является наиболее доступным типом коммуникационной среды. Это оптимальное решение для недорогих кластеров и задач, не требующих интенсивного обмена данными, а только больших процессорных мощностей, когда основная часть рабочего процесса приходится на вычисления.
Использование Gigabit Ethernet при построении кластера позволяет минимизировать бюджетные средства, поскольку стоимость интерконнекта в этом случае очень мала по сравнению со стоимостью системы. Экономия достигается также благодаря наличию встроенных контроллеров Gigabit Ethernet на многих системных платах.
Пропускная способность интерфейса составляет до 120 Мб/с. При использовании стандартных реализаций MPI (MPICH, LAM) скорость передачи данных несколько снижается — примерно до 70 Мб/сек, а латентность в лучшем случае составляет 50–120 мкс при работе библиотек MPI (правда, есть решения, позволяющие снизить задержку до 30 мкс). Множество приложений, ориентированных, в первую очередь, на скорость работы процессоров, используют такой подход: задача разбивается на части, каждый узел обрабатывает свой участок, а затем конечный результат формируется на основе вычисленных фрагментов. Для подобных задач кластеры с использованием Gigabit Ethernet интерфейса вполне применимы.
По сравнению с Gigabit Ethernet, новый стандарт 10G Ethernet обладает в 10 раз большей пропускной способностью и значительно меньшей латентностью, однако сегодня его цена довольно высока. Это обстоятельство сдерживает адаптацию 10G Ethernet в кластерных задачах.
Myrinet
Myrinet является ещё одним распространённым и достаточно универсальным типом интерконнекта для построения кластеров. Об этом говорит и то, что большая часть суперкомпьютерных систем из списка Tоп-500 самых мощных компьютеров мира построены с применением Myrinet. Но в Украине он особой популярности не завоевал главным образом из-за того, что построение мощных вычислительных систем здесь совпало с этапом активного развития технологий infiniband, которые сейчас считаются более выгодным решением по сравнению с Myrinet.
Основными преимуществами Myrinet является невысокая цена необходимого оборудования, накопленный опыт использования и наличие различного ПО и отдельных библиотек, работающих на кластерах. Новые адаптеры Myri-10G производства Myricom совместимы с коммутаторами 10G Ethernet. Это позволяет подключать их к более распространенным, но пока относительно дорогим коммутаторам 10G Ethernet.
Для построения больших сетей используются различные варианты топологии Fat Tree, а наилучшая производительность достигается при использовании Clos Network.
К программному обеспечению, которое используется при внедрении Myrinet, относится низкоуровневый интерфейс программирования GM, MPICH/GM, PVM/GM, стек TCP/IP (распространяется свободно в исходных текстах), а также коммерческие продукты — MPIPro, Scali MPI Connect.
SCI
Интерфейс SCI используется для задач, которые связаны с обработкой больших объемов данных и обменом многочисленными сообщениями небольшого размера. SCI применяется в задачах, критичных к времени задержки. В зависимости от используемых аппаратных платформ на адаптерах с интерфейсом PCI-X пропускная способность на уровне MPI может составлять до 325 Мб/сек, а латентность — всего 4 мкс.
Последние решения на базе интерфейса SCI поддерживают шину PCI-Express. При использовании шины PCI-Express достигается гораздо более высокая пропускная способность — около 900 Мб/с. При этом время задержки на пакетах MPI составляет около 1.4 мкс.
Топология сетей с интерфейсом SCI представляет собой кольцо или тор, что накладывает определенные ограничения при большом количестве узлов. Однако такая топология не требует использования коммутаторов и является идеальным решением для небольших инсталляций.
К используемому программному обеспечению относятся свободно распространяемое по лицензии GNU GPL низкоуровневое ПО от компании Dolphin (драйверы и библиотека SISCI), SCI-MPICH из Аахенского университета, а также коммерческое ПО от Scali. Существует неплохая реализация MPI второй версии стандарта для SCI от научно-исследовательского центра НИЦЭВТ из Москвы.
Компания Dolphin, производитель плат, поддерживающих интерконнект SCI, предлагает использовать свои решения в различных областях. На интернет-сайте производителя есть ссылки на решения в сфере построения высокопродуктивных кластеров для MySQL и MSSQL, систем хранения данных и др.
QsNet
QsNet является одной из самых производительных во всех отношениях разновидностей кластерного интерконнекта. Из-за высокой стоимости оборудования QsNet, как правило, применяется для построения особо крупных кластеров терафлопного диапазона.
Разработки компании Quadrics позволяют сочетать высокую пропускную способность с низкой латентностью и минимальными топологическими ограничениями. В настоящий момент существует две разновидности стандартов: QsNet и QsNet II. Более современный и мощный вариант QsNet II обеспечивает скорость передачи данных около 900 МБ/с на пакетах MPI. Минимальное время задержки передачи пакета MPI составляет около 1.2 мкс. Очень высокие скоростные характеристики и широкие возможности для масштабирования обусловливают высокую стоимость коммуникационной среды данного типа. Топология в виде Fat Tree допускает объединение в рамках одного кластера до 4096 узлов для QsNet II (до 1024 узлов для QsNet).
Программное обеспечение, которое используется для таких коммуникаций под Linux, распространяется с исходными текстами по лицензии GNU GPL и поддерживает MPI (специализированную версию MPICH) и TCP/IP.
Нишевые разработки
Помимо рассмотренных интерконнектов существуют и нишевые разработки, которые используются некоторыми поставщиками в собственных закрытых архитектурах. Так, достаточно интересным решением можно считать суперкомпьютер компании IBM BlueGene/L, использующий собственную уникальную технологию интерконнекта. Другая любопытная разработка — интерконнект BlackWidow в суперкомпьютере RedStorm производства компании Cray.
Выводы
Отрасль высокопроизводительных вычислений динамично развивается. Мощные вычислители востребованы сегодня в научных и исследовательских центрах, их применяют для инженерных расчетов, анализа и прогнозирования тенденций в области экономики, 3D-моделирования. Выбор технической реализации зависит от бизнес-требований, характерных для той или иной задачи.
С авторами статьи можно связаться по адресу: office@ustar.ua






